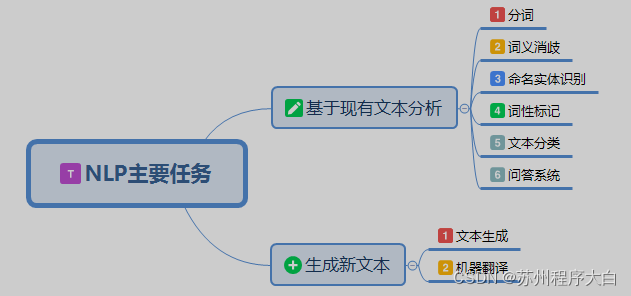
分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词...
”金融 分词 NLP“ 的搜索结果

(1): 本文针对金融领域NLP任务,使用混合数据训练构建了一个规模较小、表现优异的语言模型BloombergGPT,此前还没有专门为金融领域开发的LLM。 (2): 之前的金融领域NLP模型要么完全使用金融领域数据训练,要么使用很...
什么是自然语言处理NLP 用通俗的话来讲,自然语言处理NLP的目标是让机器能够理解人类的语言,NLP就是人和机器进行交流的技术。用专业语言来讲,自然语言处理有狭义和广义之分。狭义的自然语言处理是使用计算机来完成...

Hello 大家好,我是一名新来的金融领域打工人,日常分享一些python知识,都是自己在学习生活中遇到的一些问题,分享给大家...NLP全称Natural Language Procession,中文翻译叫做自然语言处理。通俗来说,自然语言处理其
故在做中文自然语言处理时,我们需要先进行分词。 2 中文分词难点 中文分词不像英文那样,天然有空格作为分隔。而且中文词语组合繁多,分词很容易产生歧义。因此中文分词一直以来都是NLP的一个重点,也是一个...
财经行业词库-nlp/自然语言处理


分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词...

金融方面的常见词汇形成的词典/语料库,jieba.load_userdict()即可使用
1.基本分词函数与用法 jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode) jieba.cut 方法接受三个输入参数: 需要分词的字符串 ...
点击上方,选择星标或置顶,每天给你送干货!阅读大概需要25分钟跟随小博主,每天进步一丢丢作者:华泰证券信息技术部AI算法服务团队疫情之下,全球金融市场进入大波动时代,各国金融调控政策、突...
30W+中文分词词典,覆盖广,新增金融词典
目前存在的问题有两个方面:一方面,迄今为止的语法都限于分析一个孤立的句子,上下文关系和谈话环境对本句的约束和影响还缺乏系统的研究,因此分析歧义、词语省略、代词所指、同一句话在不同场合或由不同的人说出来...


本篇文章紧接上一篇文章python金融分析小知识(9)——NLP初探之结巴分词停用词,在上一篇文章中我们通过了停用词的调用,成功将文本中一些不关键的词去掉,保留下的真正具有意义的词,本篇文章将会介绍如何通过结巴...

自然语言处理(英语:Natural Language Processing,缩写作NLP)是人工智慧和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。自然语言认知...
NLP自然语言处理技术最强学习路线 ☆☆一、自然语言处理技术的简介 ☆☆二、自然语言处理技术相关概念简介 ☆☆四、NLP...
财经常用词词库大全,用于中文分词,非常全。学习分词、自然语义分析的必备词库。适用于市面绝大部分主流的自然语言处理工具包。
自然语言处理 (NLP, Natural Language Processing) 又称为计算语言学,是一门借助计算机技术研究人类语言的科学。虽然 NLP 只有六七十年的历史,但是这门学科发展迅速且取得了令人印象深刻的成果。

来自:老刘说NLP在前面的文章中,我们介绍了关于词向量的一些基础理论和训练方法,本文主要开放汽车、房产、教育、社会、娱乐、体育、金融、科技、游戏等9大领域预训练词向量,以及字符、依存、拼音与词性4类预训练...

推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地